
 Vítejte, dnes je
sobota 11.
červenec
2026
Vítejte, dnes je
sobota 11.
červenec
2026

Součásti pro strojové učení řešené přímo na místě
Strojové učení řešené přímo v rámci zařízení má potenciál změnit od základu bezpočet produktů. Může se jednat o kategorizaci předmětů prostřednictvím obrazového snímače, gesta související s akcelerometrem nebo také věty obsažené v audio streamu. K tomu je však zapotřebí, aby související algoritmy běžely na vestavných součástkách.
Vývoj aplikací založených na strojovém učení vyžaduje zvládnutí řady technických disciplín, ale většina firem si umí sama poradit pouze s některými z nich. Za účelem vývoje, trénování, jemného ladění a také testování modelů pro strojové učení pak budou najímáni odborníci na data, systémy strojového učení a programátoři. Háček je ale v tom, že zmiňované modely obvykle neběží na vestavném hardwaru či mobilních zařízeních. Většina inženýrů znalých strojového učení takové modely na vestavném hardwaru nikdy dříve nepoužila a příslušná omezení jsou jim cizí. Abychom dokázali kvalifikované modely využít na mobilních SoC, FPGA či mikroprocesorech, bude zapotřebí je optimalizovat a omezit u nich počet možných hodnot.
Výrobci polovodičů stojí zase před úkolem vyvinout produkty, které vyhoví novým požadavkům, pokud jde o výkon, cenu a také fyzické provedení, to vše s ohledem na skutečně rychlé uvedení na trh. Flexibilita se očekává u rozhraní, vstupů i výstupů a využití paměti, takže produkty pak mohou vyhovět v řadě aplikací.
TensorFlow Lite zjednoduší optimalizaci a kvantizaci
Něco takového se v uplynulých letech poněkud zjednodušilo díky TensorFlow Lite od Googlu. Zmíněná open source platforma pro strojové učení nyní rovněž zahrnuje skripty, které lze použít při optimalizaci a kvantizaci modelů strojového učení v souboru „FlatBuffers“ (*.tflite). Využijí se přitom parametry přizpůsobené určitému aplikačnímu prostředí.
Produkt s vestavným hardwarem by měl v ideálním případě dokázat importovat soubory FlatBuffer přímo z TensorFlow bez toho, že by se musely využít vlastní či specifické optimalizační postupy, pokud jde o hardware, tedy vně takového ekosystému. Vývojáři softwaru a také hardwaru mohou proto snadno použít kvantizovaný a optimalizovaný soubor FlatBuffer na hradlových polích FPGA, SoC a také mikrokontrolérech.
OO Porovnání SoC, MCU a FPGA
Vestavné hardwarové platformy mívají pouze omezené možnosti, pro účely vývoje nejsou zase tak skvělé a složitě se budou i používat. Na druhou stranu však nabízí malou spotřebu energie, nízké náklady a také moduly s malými rozměry. Co zde umí SoC, mikrokontroléry a také pole FPGA nabídnout?
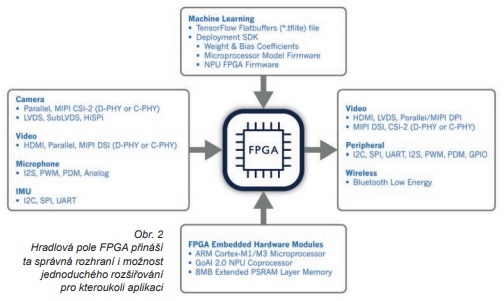
SoC nabízí nejlepší vlastnosti a mnoho standardních rozhraní, obvykle však také budou vykazovat nejvyšší spotřebu energie. Vstupy a výstupy, které jsou pro dané rozhraní specifické, však znamenají obrovskou spotřebu místa na čipu, což také představuje relativně vyšší cenu.
Výhoda mikrokontrolérů spočívá v jejich velmi nízké spotřebě energie a malém fyzickém provedení, nicméně zde budou často a do značné míry omezeny v otázkách výkonu pro strojové učení a kapacity při modelování. Modely stojící na špici produktové řady zpravidla nabízí jen speciální rozhraní, třeba pro kamery a mikrofony s digitálním výstupem.
Širokou oblast mezi mikrokontroléry a SoC konečně vykrývají pole FPGA. K dispozici je máme v celé řadě pouzder a s flexibilními vstupy i výstupy. Mohou tím v dané aplikaci podpořit jakékoli požadované rozhraní, aniž by přitom nějak plýtvaly místem na čipu. Možnosti konfigurace zde rovněž umožňují odstupňovat náklady a proudový odběr společně s výkonem a zapracovat i dodatečné funkce. Při využití polí FPGA pro systémy strojového učení však vyvstává problém spočívající v jejich nedostatečné podpoře a integraci platforem SDK, třeba jako TensorFlow Lite.
Strojové učení a pole FPGA
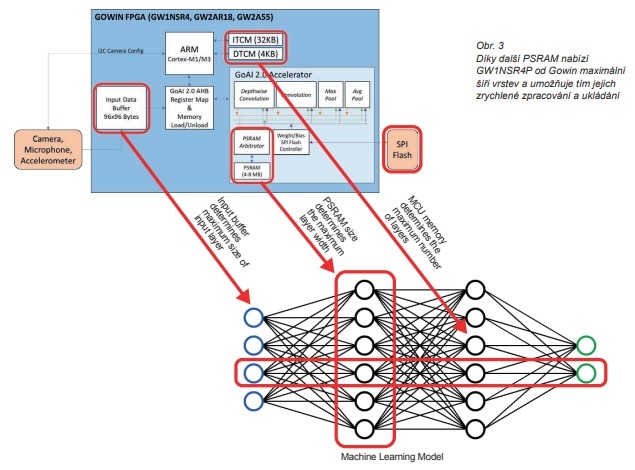
S cílem vyplnit zmíněnou mezeru nabízí Gowin Semiconductor na své platformě GoAI 2.0 SDK, takže je možné extrapolovat modely a koeficienty, generovat kód v C pro procesor ARM Cortex-M integrovaný v rámci polí FPGA a vytvářet i bitové streamy či firmware pro FPGA.
Další náročný úkol se bude dotýkat značných požadavků modelů strojového učení na paměť Flash a RAM. Nové hybridní μSoC FPGA, třeba jako GW1NSR4P od Gowin, vyhovují zmíněným potřebám díky zapracování dodatečné PSRAM o velikosti 4 až 8 MB. GW1NSR4P nabízí speciální GoAI 2.0 coprocessor pro rychlejší zpracování a ukládání vrstev (folding a pooling).
Použije se ve spojení s jeho hardwarovým IP jádrem Cortex-M pro řízení parametrů vrstev, zpracování modelu a výsledky výstupu.
Pro své odběratele, kteří vestavný hardware využijí ke strojovému učení, spousta dodavatelů programovatelných polovodičů v rámci návrhu rovněž nabízí služby – programy umožňující dosahovat strmějších křivek učení. Gowin zde není žádnou výjimkou – GoAI v takovém případě pomáhá uživatelům hledajícím jednočipové řešení s klasifikací nebo asistencí při implementaci testovaných a kvalifikovaných modelů z „běžné nabídky“, kteří však neví, jak by měli komunikovat s vestavným hardwarem.
Zmíněné typy programů dodavatelé zajišťují s cílem pomoci firmám využívat méně prostředků, pokud jde o strojové učení a implementace na vestavném hardwaru (TinyML), takže se mohou nyní lépe soustředit na vlastní vývoj produktu.
Závěr
Popularita vestavného a lokálně řešeného strojového učení v očích mnoha vývojářů neustále roste.
Inženýři znalí celé řady oblastí či oborů, od kterých se očekává vývoj takových systémů, však musí počítat s úkoly, které nemusí být vůbec jednoduché. Někteří dodavatelé programovatelných polovodičů na takovou potřebu reagují s oblíbeným ekosystémem nástrojů pro vestavný hardware a nabídkou součástek s flexibilním rozhraním, rozšířenou pamětí, novými softwarovými nástroji a také službami usnadňujícími návrh.
